
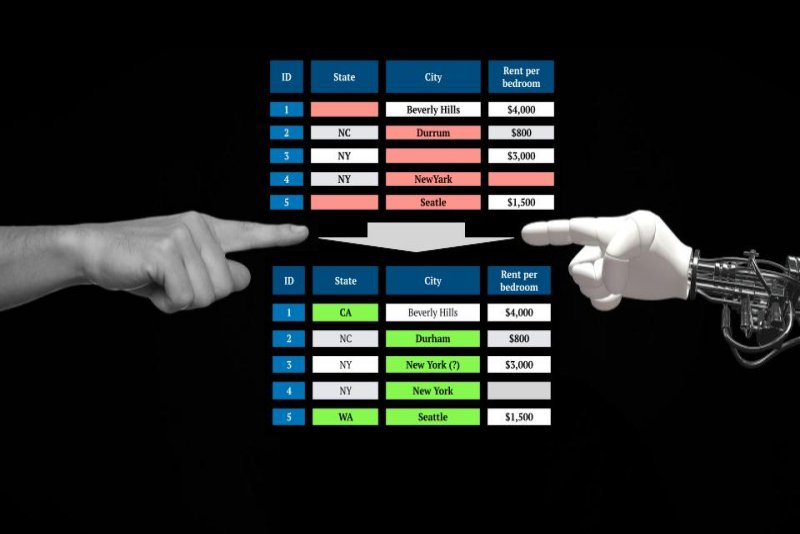
MIT researchers have created a new system that automatically cleans “dirty data” — the typos, duplicates, missing values, misspellings, and inconsistencies dreaded by data analysts, data engineers, and data scientists. The system, called PClean, is the latest in a series of domain-specific probabilistic programming languages written by researchers at the Probabilistic Computing Project that aim to simplify and automate the development of AI applications (others include one for 3D perception via inverse graphics and another for modeling time series and databases). According to surveys conducted by Anaconda and Figure Eight,…


