
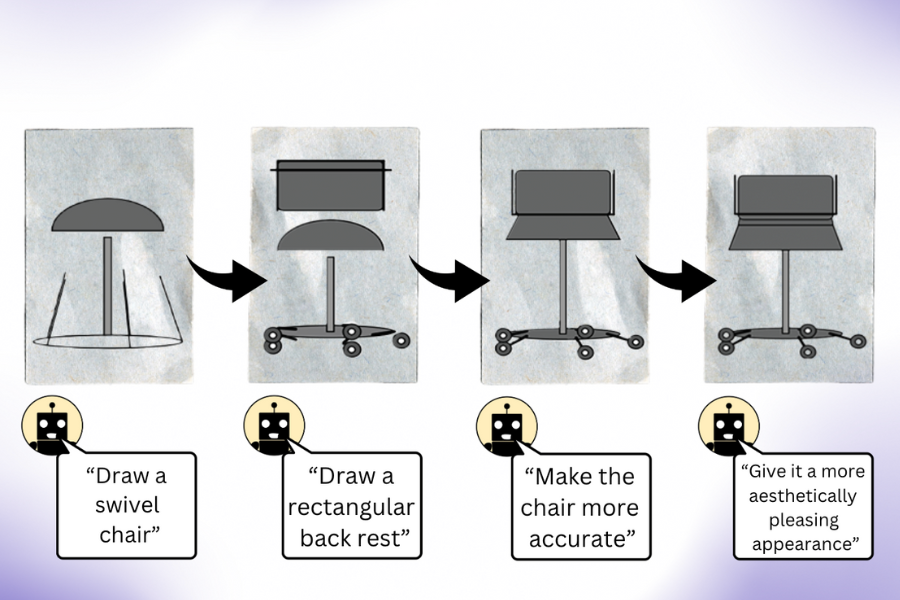
You’ve likely heard that a picture is worth a thousand words, but can a large language model (LLM) get the picture if it’s never seen images before?As it turns out, language models that are trained purely on text have a solid understanding of the visual world. They can write image-rendering code to generate complex scenes with intriguing objects and compositions — and even when that knowledge is not used properly, LLMs can refine their images. Researchers from MIT’s Computer Science and Artificial Intelligence Laboratory (CSAIL) observed this when prompting language…


